|
|
|
I have built the GNU compiler GCC as a cross compiler between
my Linux host (which runs on an Intel Pentium station) and a
diskless PowerPc target running vxWorks.
This means that:
- You build the vxWorks kernel on the Linux station.
- You use the kernel you've built to boot a PowerPc station.
This project gave me a hard time. The most difficult tasks were:
- Downloading all the GNU tools:
- GCC (the compiler)
- The binutils (the assembler as, the
linker ld, ...).
- Several patches to apply to the binutils and
to the GCC compiler.
- Compiling everything (it does not work rigth the first time).
You need a apply several patches in order to compile everything. It
took me about 2 months to figure out what was missing.
- Configuring the development environment (so the cross compiler calls
the cross assembler and not the native assembler for example).
- Modify all Tornado/BSPs configuration files so that the paths are
consistent.
- Copy all the vxWorks libraries to the linux station.
- You think it is finished? NO! There is another very tricky part: the
munch utility. This is painful! You think you have done everything
and you realize that you are missing the munch utility. I have
found a awk script to do that. Note the under Tornado 2 they
use a TCL script (so you can use it as is on the Linux box).
On your Intel Pentium host you build kernels for a PopwerPc target. This
project was much more easier that the first one because Linux is much
more documented that vxWorks. Also you don't have any problem to build
the cross tools.
A cryptographic program (written in C) for UNIX and Windows that allows you to:
- Crypt/Decrypt using the RSA agorithm.
- Generate RSA keys (any length).
- Test RSA keys.
- Crypt/Decrypt using the IDEA agorithm.
- Generate 20 bytes imprit of a file using the SHA algorithm.
- Safely delete a file (a simple "rm" or "del" is not enough ...).
Note about the implementation:
- Almost fully portable. The code can be compiled on any OS with an ANSI C compiler. The only part that may not be fully partable is the random number generator (but this can be easily adapted !).
- Big endian / Little endian compatible. The format of the files on the disk in always the same.
- Fully documented: I have written absolutely every thing (from A to Z). Each mathematical algorithm (for RSA) is completly detailed.
- heavily tested under many OS and many hardware: PC (Linux / Dos 13 bits / Dos 32 bits), Sparc (Sun OS and Sun Solaris 2.5.1), RS6000 (AIX, many version).
- Modular design. Example: the RSA part of the code is almost independent of the rest of the code. Only few I/O utility functions are shared between modules.
- No dynamic memory allocation: The RSA ALU (Arithmetic and Logical Unit) is quite complex, no dynamic memory allocation makes the code stronger (no risk of memory leak... guaranteed).
- Clean code: no warning at all during the build process (GCC with "-Wall" option / Borland C++ 5.0 with all warning messages activated / xlC (IBM AIX compiler) with all warning messages activated / Solaris compiler with all warning messages activated).
Note about memory allocation:
Dynamic memory allocation is very attractive, but it makes the code much more difficult to maintain. All allocated memory must be freed, otherwise you create a "memory leack". If the code is complex, it is quite easy to forget to free a previously allocated memory (even if you are very scrupulous).
Another point is that dynamic memory allocation may generate a significant overhead under multitasking/multiuser operating system. Especialy when "memory allocation"/"memory free" is heavily used. Operations on very long integer used by RSA are long (especialy with very long keys like 2048 bytes). Some part of the UAL code are heavily used, dynamic allocation in this case may slow down significantly the crypt/decrypt process.
On the other hand, no dynamic memory allocation makes the use of the software less handy. If the encrypted file has been crypted using a 128 bytes key, you need a version of the software compiled for 128 RSA key to decrypt it. You can use a version compiled for longer keys, but it will be slower.
Note about portability:
99% of the code is really fully portable (only the random number generator may need to be modified). This makes the program slower. Each machine, each compiler, each OS has its own particularities. The use of such particularities produce faster programs but the program becomes non-portable.
Example:
- GCC extensions (like "inline functions") may be useful but other compilers (like IBM xlC) does not accept it.
- The use of "register" variables may accelerate the program. Unfortunately registers are "CPU/OS specific".
- We could write parts of the code in assembler, but it is not portable at all.
- Some UNIX systems (at kernel level) allow "task locking" (scheduler disabled) and/or "memory locking" (swap disabled). Part of the program could be implemented as driver, so we could use these possibilities. But this makes the prgram very complex and not portable at all.
Of course, conditional compilation could have been used but you can't write optimized code for all platforms unless you are an "multi-expert".
Conclusion:
RSA is difficult to implement because:
- It is difficult to find the good algorithms for the Arithmetic and Logical Unit. By "good", I mean fast. The following algorithms gave me a hard time:
- The division. Seems easy ... but don't forget that you manipulate very long unsiged integers (128 bytes and more). Finding a FAST algorithm is NOT so easy ;).
- The "modular inversion". First you must understand it and then you must find a fast algorithm (I have mainly consulted the books "The art of computing" and the "applied cryptography" - plus others - for the algotithm).
- The prime number generator. I use a "probabilistic test", the classic method (you learn at school) is to slow (it takes for ever) with very long integers.
- The random number generator (I don't generate truly random numbers ... but it is good enough).
- The "modular power": imagine a 1024 bytes integer "power" a 1024 bytes integer, you obtain a 2048 bytes integer ! This is huge and it takes for ever to calcul it. Fortunatly the algorithm was easy to find in the mathematical literature.
- It is very difficult to test. Your computer uses 32 (may be 64) bits integers ... you have nothing to compare. Testing everything took me very long time.
The final test:
- generate a random file (random size up to 2Gb, and random content) --- crypt it --- decrypt it --- compare : the original file and the decrypted file must be identical.
Write a script to do the previous test automatically. If there is one error the script stop with a error message
Run this script during 2 weeks on several OS.
- Same but use 2 computer (with different architecture: like PC and RS6000) connected by a network link.
- Computer A crypt the file and send it to computer B.
- Computer B decrypt the file and send it to computer A.
- Computer A compare the original file with the decrypted file.
Write a script to do the previous test automatically. If there is one error the script stop with a error message
Run this script during 2 weeks.
- Same as previous test but inverse A and B.
My main objective was to write a robust, portable, easy to maintain (add extra functionalities) and reasonably fast cryptographic utility. IDEA and SHA algorithms are very simple but I found RSA very difficult to implement.
Using the same code (RSA only) than the previous program but with a C++ encapsulation. The C++ makes dynamic memory allocation easier (and safer) to use that C (constructors / destructors). The alogorithms are the same (almost copy/paste of the C code) the only difference is: the "object manipulation overhead" and the "memory management overhead".
. The result is:
- arbitrary key lenght (No need to recompile the program).
- slower that C implementation.
With small keys (less than 128 bytes) the difference of speed is acceptable. But with long keys (256 bytes and more) the C++ implementation is really slow. With 1024 bytes long keys it is terrible ...
The C++ implementation of RSA you can find with my resume is not good (I have done it in purpose). Do not use it to crypt anything ... The algorithms are modified.
This sniffer allows you to dump all messages transmited on your ethernet network. You can dump:
- The ethernet header.
- The IP headers.
- The UDP headers.
- The TCP headers.
- the application data (following the UDP/TCP header).
- All other protocols (IGMP, ICMP, ...) headers and data.
The program can be configured to (command line options):
- Select protocol(s) to dump (ex: "UDP only", "TCP only", "IGMP" or "TCP and UDP only").
- Dump only messages from or to a specific port (ex: "messages to port 25 only", "messages from port 123 only", "messages from port 2100 to port 25 only", ...).
- Dump only messages from or to a specific host (ex: "messages from host 92.0.0.1 only", "messages to host 92.0.0.3 only", "messages form host 92.0.0.1 to host 92.0.0.2 only", ...).
- Dump or hide any kind of header (ex: "dump IP header only", "dump UDP header only", "do not dump any header", ...).
- Gives extra information about the header (gives label for each field + perform checkings + gives the meaning of field values) ... useful.
- Dump or hide application data (in ascii only, in hexa only or in hea/ascii).
| usage |
When you type netdump with no options, it prints out the usage.
netdump [udp {on|off}] [tcp {on|off}] [igmp {on|off}]
[from_ip IP_mask] [to_ip IP_mask] [from_port port_number]
[to_port port_number] [body_as {none|ascii|hexa|mix}]
[ip_hd {on|off}] [udp_hd {on|off}] [tcp_hd {on|off}]
[eth_hd {on|off}] [verbose] [{short_desc|long_desc}]
interface
netdump help
interface: name of the interface to look at (ex: "eth0").
You can use the "ifconfig" command to print
the list of all available interface on your
system.
Options:
udp : - on - dump UDP packets
- off - ignore UDP packets
tcp : - on - dump TCP packets
- off - ignore TCP packets
igmp : - on - dump IGMP packets
- off - ignore IGMP packets
from_ip : dump packets from hosts whose IP addresses
match the mask.
to_ip : dump packets to hosts whose IP addresses
match the mask.
from_port: dump packets from port 'port_number'
to_port : dump packets to port 'port_number'
body_as : - ascii - dump packet body in ascii.
- hexa - dump packet body in hexa.
- mix - dump packet body in hexa and ascii.
- none - do not dump packet body.
ip_hd : - on - dump IP headers.
- off - do not dump IP headers.
udp_hd : - on - dump UDP headers.
- off - do not dump UDP headers.
tcp_hd : - on - dump TCP headers.
- off - do not dump TCP headers.
eth_hd : - on - dump ethernet headers.
- off - do not dump ethernet headers.
short_desc : short header's description.
long_desc : long header's description.
An IP mask is an IP address in doted decimal notation. The special
character '@' means "any number between 0 and 255".
ex of valid IP masks: 192.45.65.10
192.45.65.@
192.45.@.@
|
| Default settings |
output of "./netdump eth0" (eth0 is the name of the network interface). For security
reasons, the ethernet addresses and the IP addresses have been changed.
### Ethernet header ###
ETH destination address : 0:e1:1e:66:5b:5e
ETH sender address : 8: 0:5a:57:39:51
ETH type : 0x800 (IP)
### IP header ###
IP version : 4
IP header length : 5 (4*5=20 bytes)
IP type of service : precedence - 000 (Routine)
Delay - 0 (Normal)
Throughput - 0 (Normal)
Reliability - 0 (Normal)
IP total length : 425 bytes
IP id : 39609
IP flags : bit number 1 - 0 (May Fragment)
bit number 2 - 0 (Last Fragment)
IP fragment pos : 0 (0*8=0 bytes)
IP ttl : 60
IP protocol : 6 TCP
IP checksum : 38271
IP source : 92.0.0.4
IP destination : 209.172.131.31
### TCP header ###
TCP source port : 1523
TCP destination port : 80
TCP sequence number : 2349613376
TCP ack number : 431477430
TCP header length : 5 (4*5=20 bytes)
TCP reserved bits : 000000
TCP urgent flag : 0
TCP ACK : 0
TCP Push flag : 0
TCP Reset flag : 1
TCP SYN : 1
TCP FIN flag : 0
TCP window size : 16384
TCP checksum : 41790
TCP urgent pointer : 0
74 54 45 02 F2 36 76 96 D2 26 96 E6 F2 GET /cgi-bin/ -a-
35 F6 66 47 34 16 27 47 E2 56 87 56 F2 SoftCart.exe/ -a-
36 56 E6 47 27 16 C6 67 16 36 57 57 D6 centralvacuum -a-
37 F2 26 56 16 D6 96 E6 66 F6 E2 86 47 s/beaminfo.ht -a-
D6 C6 F3 C4 B2 37 36 37 47 F6 27 56 B2 ml?L+scstore+ -a-
D6 86 97 67 13 23 13 43 B2 93 53 53 13 mhyv1214+9551 -a-
63 23 73 83 73 02 84 45 45 05 F2 13 E2 62787 HTTP/1. -a-
03 D0 A0 25 56 66 56 27 56 27 A3 02 86 0 Referer: h -a-
47 47 07 A3 F2 F2 77 77 77 E2 D6 96 46 ttp://www.mid -a-
16 D6 56 27 96 36 16 D2 16 07 07 C6 96 america-appli -a-
16 E6 36 56 E2 36 F6 D6 F2 36 76 96 D2 ance.com/cgi- -a-
26 96 E6 F2 35 F6 66 47 34 16 27 47 E2 bin/SoftCart. -a-
56 87 56 F2 36 56 E6 47 27 16 C6 67 16 exe/centralva -a-
36 57 57 D6 37 F2 26 56 16 D6 E2 86 47 cuums/beam.ht -a-
D6 C6 F3 C4 B2 37 36 37 47 F6 27 56 B2 ml?L+scstore+ -a-
D6 86 97 67 13 23 13 43 B2 93 53 53 13 mhyv1214+9551 -a-
63 23 73 53 13 D0 A0 34 F6 E6 E6 56 36 62751 Connec -a-
47 96 F6 E6 A3 02 B4 56 56 07 D2 14 C6 tion: Keep-Al -a-
96 67 56 D0 A0 55 37 56 27 D2 14 76 56 ive User-Age -a-
E6 47 A3 02 D4 F6 A7 96 C6 C6 16 F2 33 nt: Mozilla/3 -a-
E2 03 13 02 82 85 13 13 B3 02 94 B3 02 .01 (X11; I; -a-
14 94 85 02 23 92 D0 A0 84 F6 37 47 A3 AIX 2) Host: -a-
02 77 77 77 E2 D6 96 46 16 D6 56 27 96 www.midameri -a-
36 16 D2 16 07 07 C6 96 16 E6 36 56 E2 ca-appliance. -a-
36 F6 D6 D0 A0 14 36 36 56 07 47 A3 02 com Accept: -a-
96 D6 16 76 56 F2 76 96 66 C2 02 96 D6 image/gif, im -a-
16 76 56 F2 87 D2 87 26 96 47 D6 16 07 age/x-xbitmap -a-
C2 02 96 D6 16 76 56 F2 A6 07 56 76 C2 , image/jpeg, -a-
02 96 D6 16 76 56 F2 07 A6 07 56 76 C2 image/pjpeg, -a-
02 A2 F2 A2 D0 A0 D0 A0 */* -a-
Note: the "-a-" means "here you have an ASCII text". This makes very easy the search for
ASCII text (just do a "grep -a-").
|
| But I want a short header description ! |
No problem, just use "./netdump short_desc eth0"
Ethernet type: 0x800 (IP)
IP : 92.0.0.4 => 209.143.242.142
Port : 1061 => 53 (UDP)
44 D1 00 00 00 10 00 00 00 00 00 00 90 D -a-
16 17 57 16 C6 96 E6 57 87 80 86 F6 D6 aqualinux hom -a-
56 07 16 76 56 30 36 F6 D6 00 00 10 00 epage com -a-
10
Note: you can eliminate some (or all) headers with the following options:
- ip_hd off
- tcp_hd off
- udp_hd off
- eth_hd off
|
| I don't care hexa stuffes ! I want to read e-mails ;) |
Do not use netdump to read co-workers e-mails !!! But anyway you can dump the data
in ascii if you really want: "./netdump short_desc body_as ascii eth0"
Ethernet type: 0x800 (IP)
IP : 208.178.22.197 => 92.0.0.4
Port : 80 => 1533 (TCP)
--- Start of ASCII data ---
Only ascii data will be printed here
--- End of ASCII data ---
|
| Now I want hexa only ! |
OK ... "./netdump short_desc body_as hexa eth0"
Ethernet type: 0x800 (IP)
IP : 92.0.0.5 => 134.56.3.102
Port : 1061 => 53 (UDP)
44 62 00 00 00 10 00 00 00 00 00 00 60
16 57 47 86 03 33 20 E6 37 20 57 57 30
E6 56 47 30 36 F6 D6 00 00 10 00 10
|
| Other configuration |
I can't show all the combinations for the options ... But for example you could type:
"./netdump short_desc body_as ascii from_ip 92.0.0.1 to_port 25 udp off igmp off eth0"
You dump (in ascii) every TCP connexion from the host 92.0.0.1 to the port 25 of any host.
Do you know what it means ? If not, I won't tell you ... Anyway netdump should be
used ONLY to debug network aplications.
|
Unlike the famous "tcpdump", this sniffer gives a complete description of Ethernet/IP/UDP/TCP
headers (all fields of the header is dumped with checking and explanations).
Also this sniffer dumps the application data in a very easy to read format.
- Supported OS:
- Written in C.
Note about NT implementation
Because under Windows the network is not as easy to access that under Linux, the implementation of the sniffer is much more complex:
- One main thread used to control global resources.
- 3 receiver threads used to get packets from the network adaptator.
- 1 "rotating" buffer used to stored packets.
- 1 printer thread used to dump packets' content.
The 3 receivers get packets from the network adaptor and store it into the rotating buffer. The printer thread reads packets from the rotating buffer and dump the content on the screen.
The main points are:
- Synchronization between receivers.
- Synchronization between receivers and the printer for buffer access.
- Resource management: all allocated resource must be freed, all open handler must be closed, all mutex must be released, threads must terminate properly, ...
- Clean error recovery: If an error occurs we must perform an exit as clean as possible.
This C library makes CGI programs in C very easy to write. This library supports "file uploads". To write it I have consulted the following documents:
- INTERNET-DRAFT about HTTP/1.1 and later.
- INTERNET-DRAFT about The WWW Common Gateway Interface (version 1.1).
- One RFC (I don't remember the number) about file uploading.
All the "FORM data" (name, value) are placed into a linked list. If the CGI script receives a file, this file is stored in a temporary file and the name the this temporary file is written in the "linked list".
The user does not have to worry about memory allocation (for the linked list). The user code takes place in the function called cgiMain. This function is called in the main function. The main function:
- initialize the linked list.
- read the standart input to extract "FORM data".
- put "FORM data" into the linked list.
- call the cgiMain function.
- delete the linked list.
- delete temporary files if necessary.
Portability:
This library is almost fully portable. I use Flex, the GNU version of Lex, but today you can find Flex on almost any OS ... including windows. Anyway the "Flex part" of the code can be easily re-written if necessary (but it is really boring and the code becomes less easy to maintain). Note that the "Flex part" does not use any Flex specific extension (you can use Lex if you prefer).
Simple example of CgiMain::
Note that I have written functions to manipulate the linked list (to mask the structure of the linked list). But this example is very simple.
#include <stdio.h>
#include "parser.h"
#include "cgi.h"
#include "pile.h"
#define P_ERROR(x) { \
fprintf (cgi_err, "<HTML><BODY>"); \
fprintf (cgi_err, "<BR><BR><B>CGI ERROR: %s </B><BR><BR>", x); \
fprintf (cgi_err, "</BODY></HTML>"); \
}
int CgiMain(Base *b, FILE* cgi_out, FILE* cgi_err)
{
char buff[FILE_NAME_SIZE];
int rc;
if (b->nb_elem != 1)
{
P_ERROR("Invalid linked list");
return ERROR;
}
if (((b->first_elem)->data)->filename[0] == 0)
{
P_ERROR("No file has been selected !");
return ERROR;
}
if (((b->first_elem)->data)->tempfile[0] == 0)
{
P_ERROR("no file has been uploaded !");
return ERROR;
}
sprintf (buff, "/home/ftp/inbox/%s", ((b->first_elem)->data)->filename);
rc = Rename_File (((b->first_elem)->data)->tempfile, buff);
if (rc != 0)
{
P_ERROR("CGI ERROR while renaming the temporary file");
return ERROR;
}
fprintf (cgi_out, "<HTML><BODY>"); \
fprintf (cgi_out, "<BR><H1>File upload result:</H1><BR><BR>");
fprintf (cgi_out, "<H2>Your file has been successfully uploaded in:</H2>%s", buff);
fprintf (cgi_out, "</BODY></HTML>"); \
return OK;
}
|
The bootp daemon is used to boot diskless station over the network (the diskless station only knows its hardware address). The BOOTP protocol is fully described in the RFC number 951. My own version of bootpd:
- check the syntax of the "/etc/bootptab" file.
- can dump all the bootp requests (usually broadcasts) on the network. It dumps the messages in a text file well formated and easy to read.
- can dump all bootp answers on the network (if ARP not used <=> the answer is a broadcast).
- only supports ethernet address (because I only needed this kind of addresses).
- does not support ARP cache manipulation (this is OS specific - not portable). But most public versions of bootpd don't support ARP manipulation anyway (the bootp answer is a broadcast).
- does not support gateways (the bootp server must be on the same network) because I did not need it.
I have written it because I needed to dump all the bootp requests and bootp answers on my network (for debugging).
Note: The network module (socket management) can be compiled under most UNIXs (tested under Sun, Linux, AIX, Lynx OS and vxWorks) and under Windows (tested under 95/98/NT/2000) too. Under Windows I use the standart Berkeley Sockets (requires "winsock.dll").
A simple implementation of a mail client in C. To do that I have consulted the RFC 821 that describes the Simple Mail Transfer Protocol. Note that the network module is the same than for the bootp program. so this mail client can be compiled under UNIX and Windows.
Remark:
- To send mail you can use telnet (you connect to the port number 25 and you type the SMPT commands as described in RFC 821).
- SMTP requires a TCP (ie: connected) connection. Therefore the IP address of the sender is known by the receiver. If you look at the mail header you can see the IP addresses of all the hosts that have forwarded your mail => "anonymous e-mail is (almost) a dream".
- To send anonymous e-mail you can use remailers. With the last version of remailers it is very difficult (if you know how to use it) to find the origine of the e-mail, almost impossible (unless may be for the FBI - if all the remailers used are in the US territory).
For more information about remailers visit the Cypherpunk page.
A TeX editor written with Borland C++ 5.0 (OWL) for Windows 95/NT. This editor has almost averything you need to write TeX documents (with a very nice grapical interface). You can call TeX just by clicking on a button (then DviWin is called if no error).
This programs (written in C) allow you to synchronize task running on several machines connected by a TCP/IP network. Locally each task handles "network semaphores". The programming interface provided by my library is very simple.
Notes:
- This programs uses the sames network module that the bootp program. It means that it can runs under UNIXs or Windows.
- Tested with PowerPc targets running vxWorks (real time operating system).
- Tested with PowerPc targets running AIX.
- Tested between PowerPc targets running vxWorks and AIX.
- Tested between PowerPc targets running vxWorks and AIX and a PC target running Linux.
Nowdays it is very common to access databases over the network using a
web browser. As I have already done a lot of work about CGI, I wanted to
know how to interface a database to the net. Therefore I decided to
create a simple, but useful (at least for me), address book that I could
access over the network. The information (first name, last name, phone
number, ...) is stored into a relational database that can be accessed
over the network.
In order to do that, I needed:
- An operating system.
- A relational database.
- A web server.
- A small network to test the project.
The operating system
For the operation system I chose Linux for the following reasons:
- Linux is highly adapted to networking applications (like all-UNIXs).
In fact there is no better operating system for networking.
- The documentation available is really excellent and easy to find,
so you don't waste time your searching for information. And if you really
have a problem the online community provides a precious help.
Furthermore the Linux documentation is really accurate: it uses the
right terms so you are not confused.
Have you ever read a Microsoft manual? I have looked at the one for
Microsoft Frontpage. This manual really sucks! It tells you how to use
the Frontpage's graphical user interface to create a so called web site
but:
- The vocabulary used is specific to Frontpage. This vocabulary is used
only with Frontpage and has nothing to do with the real (accurate)
vocabulary used on the Internet.
- Microsoft does't tell you anything at all about how things work. So, for
most users, they have to buy the Microsoft WEB solution if they want to
build their own web site.
Conclusion: if you use Microsoft Frontpage you really don't know
anything about WEB design and how things work. You are totally dependent
on Microsoft ...
The web server
For the web server I did not choose the one from Microsof as you should
have guessed. I could because when you really know how a web server
works you can take any of it. But, as you understood, I am really fed up
with Microsoft ...
Anyway there is a much better web server than the Microsoft one: Apache.
- Apache is faster.
- Apache is well documented with accurate information.
- Apache is open source, you are sure that there is no hidden features or security holes.
- Apache is used by the biggest WEB companies (Yahoo, Alatavista, AOL, ...). Studies show that 80% of web servers run Apache.
- Apache is free.
The database
For the database I choose PostgreSQL. I could not afford to buy Oracle
or any commercial database.
I have been really surprised by the high quality of PostgreSQL:
- It compiles without any problem under Linux, AIX and SUN.
- The installation is straightforward.
- The documentation is accurate and really good, especially the book
from Bruce Momjian (available on-line).
- You have a wide choice of languages available for interfacing the
database.
To interface the database I chose C for the following reasons:
- I have already written and well tested a C library to receive
information from the web server. This library makes easy to write CGI
interfaces.
- The PostgreSQL C library is really easy to use.
C may not be the most productive way to write CGIs. But by using C you learn all the details and this is extremely important because you get a deep understanding of how things work. You can then use a higher level development tool easily.
Security issues
When writing CGI in C you should be very careful regarding security.
Several hackers' attack is possible and if your program is not well
designed, a smart hacker could break down your system.
A good CGI library should be easy to use and generic (so you can re-use
it). This implies memory allocation, which can be very dangerous if you
are not careful.
In the application code itself you should also check for bad data from
the WEB server. Depending on what you are doing, a wrong value might
crash your system (delete important files like the password
database, ...).
Also you should take extra care about UNIX administration. Don't SETUID
your CGI as root unless it is really indispensable (try anything to
avoid it because this is the best thing you can do to allow a hacker to
break your system).
General structure
| Client/server structure |
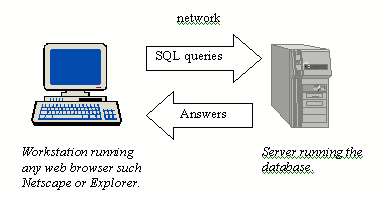
|
| Server details |
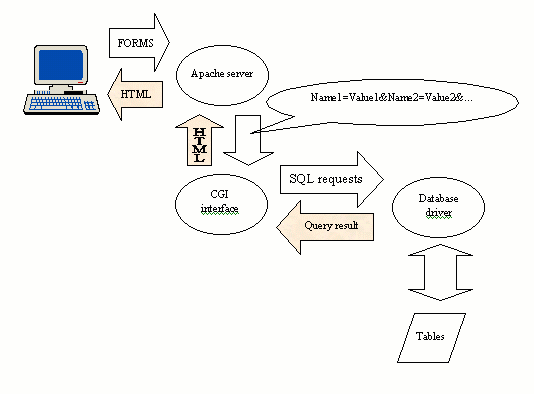
|
C code sample
I can't show here all the source code used for this project. I'll just
present the source code for the CGI that is responsable for adding a new
record to the database. What you see here is only the "Cgi_Main()" function.
All the code that read the input from the WEB server is not shown. The code structure is:
- Read the input from the web server and perform appropriate tests to
prevent us against hacker's attack (for example we first check the size
of the message).
- Extract the couples (name=value) from the message and store it into a
linked list.
- Call the Cgi_Main() function. This function is responsable for
accessing the database. Note that we check all the information
from the web server.
- Delete the linked list and then exit.
|
| sample source code: add a record in the address book |
#include <stdio.h>
#include <unistd.h>
#include "cgi.h"
#include "pile.h"
#include "libpq-fe.h"
#include "address_book.h"
#define P_ERROR(x) { \
printf ("<HTML><BODY>"); \
printf ("<BR><BR><B>CGI ERROR: %s </B><BR><BR>", x); \
}
int Cgi_Main(Base *b)
{
int i;
Elem *e;
char query[MAX_SQL_LENGTH]; /* SQL query */
PGconn *conn; /* database connexion */
PGresult *res=NULL; /* Query result */
char *c;
char list[MAX_SQL_LENGTH];
/**********************************************************/
/* We must have 31 entres exactly */
/**********************************************************/
if (Get_Nb_Elem(b) != COLUMN_NUMBER)
{
P_ERROR("Invalid entry");
return ERROR;
}
/**********************************************************/
/* check that the names are valid */
/**********************************************************/
if (Check_Form_Names(b) == ERROR) { return ERROR; };
/**********************************************************/
/* check that the value length are valid */
/**********************************************************/
if (Check_Value_Lengths(b) == ERROR) { return ERROR; };
/**********************************************************/
/* Now make sure that we have at least the fisrt name and */
/* the last name. */
/**********************************************************/
e = (Elem*)Get_First_Elem(b);
c = (char*)Get_Value(e);
if (*c == 0)
{
P_ERROR("You must enter a first name.");
return ERROR;
}
e = (Elem*)Next_Elem(e);
c = (char*)Get_Value(e);
if (*c == 0)
{
P_ERROR("You must enter a last name.");
return ERROR;
}
/**********************************************************/
/* Connexion to the database */
/**********************************************************/
conn = (PGconn*)PQconnectdb("dbname=address_book");
if (PQstatus(conn) == CONNECTION_BAD)
{
P_ERROR("Can not connect to the database");
return 1;
}
/**********************************************************/
/* At this point the entries should be correct. */
/**********************************************************/
printf ("<HTML>");
printf ("<HEAD><TITLE>Add record</TITLE></HEAD>");
printf ("<BODY>");
printf ("<TABLE BORDER=2 CELLSPACING=3 CELLPADDING=3 WIDTH=100%>");
printf ("<TR VALIGN=center>");
printf ("<TD ALIGN=center BGCOLOR=\"#FAEBD7\">");
printf ("<H1>Adding a record</H1>");
printf ("<A HREF=\"http://%s/address_book.html\">Back to main menu</A>", SERVER_IP);
printf ("</TABLE>");
/**********************************************************/
/* Create the query */
/**********************************************************/
Add_To_String (query, "", RESET_POS);
/* <=== ===> */
Add_To_String (query, "INSERT INTO data (", ADD);
Create_List(list, b, ",", NAME_WANTED);
Add_To_String (query, list, ADD);
Add_To_String (query, ")", ADD);
/* <=== ===> */
Add_To_String (query, "VALUES (", ADD);
Create_List(list, b, ",", VALUE_WANTED);
Add_To_String (query, list, ADD);
Add_To_String (query, ")", ADD);
/**********************************************************/
/* Show SQL query */
/**********************************************************/
#ifdef DEBUG_SQL
printf ("<TABLE BORDER=2 CELLSPACING=3 CELLPADDING=3>");
printf (" <TR VALIGN=center>");
printf (" <TD ALIGN=center BGCOLOR=\"#DDDDDD\"><B>SQL command</B>");
printf (" <TR VALIGN=center>");
printf (" <TD ALIGN=left BGCOLOR=\"#DDDDDD\">");
printf ("<PRE>%s</PRE>", query);
printf ("</TABLE>");
#endif
printf ("<BR><BR>");
printf ("The following record has been added to the address book:");
printf ("<BR><BR>");
Print_File(b);
/**********************************************************/
/* Send the query */
/**********************************************************/
res = PQexec (conn, query);
if (PQresultStatus(res) != PGRES_COMMAND_OK)
{
printf("\nCan not execute query\n");
printf ("\n\n==> %s", PQerrorMessage(conn));
PQclear (res);
PQfinish (conn);
return ERROR;
}
/**********************************************************/
/* Printing summury */
/**********************************************************/
if (res != NULL) { PQclear(res); }
PQfinish(conn);
return OK;
}
|
Screen shots
The two following links show you samples of what you see when you access the address book over
the network. But do **NOT** try to use the address book because it won't work. In order to access it you should have access to my web server which IP address is "192.70.56.20".
But this server is not accessible from outside our firewall
Click here to see the the HTML page used to add a record to the address book.
Click here to see the the HTML page used to search for a record.
I have taken over the previous project (PostgreSQL interfaced using C
libraries) but I've decided to rewrite the CGIs in JAVA. The connection
with the database is done using JDBC.
Because JAVA is interpreted the CGIs don't need to be recompiled when
you copy it to a new platform. Also the JDBC interface is portable
between databases. The drawback of course is that these CGIs are very
slow comparing to the one written in C. But for the address book this
was not an issue.
This command line program allows you retrieve an HTML document. You specifies the following parameters:
- The HTTP server's host.
- The document's path.
- The port number (should be 80).
- The document part you want to get (for single thread version only).
- A timeout.
- Number of threads (for multi thread version only).
| argument
| description |
| host_address
| Host name or UP address of the server's host (ex: www.yahoo.com) |
| document_path
| Path to the document (ex: /index.html) |
| port
| Server's port (should be 80 for HTTP) |
| document_part
| Defines what you want to get.
- all: get everything.
- header: get only the HTTP header.
- status: get only the HTTP status line.
|
| timeout
| Timeout in second. |
| Number_of_thread
| Up to 64 threads under NT.
|
The program can be compiled under the following OS:
- Linux (using the GNU compiler's tool chain).
- SUN (using the GNU compiler's tool chain).
- Windows (NT4.0/95/98/2000) (using Visual C++ 6.0).
I provide one "Makefile" for each system. The source code is made of the following set of files:
| File
| Description |
| depend.h
| Defines preprocessor's macros depending on the target OS. |
| sockets.h
| This header file takes care of systems' dependencies regarding sockets' management. |
| http.hpp
| Class HTTP's declaration. This class has the same interface regardless of the target system. |
| sockets.cpp
| Low level sockets' management (system dependant). |
| http.cpp
| Class HTTP's implementation. |
| single_thread.cpp
| Application's main code for the single thread version (high level code). |
| multi_thread_win.cpp
| Application's main code for the multithreaded version (windows only). |
| Makefile_win
| Makefile for Microsoft Visual C++ 6.0. |
| Makefile_linux
| Makefile for the GNU compiler tool chain for Linux. |
| Makefile_sun
| Makefile for the GNU compiler tool chain for Sun. |
| sources
| ZIP file of all sources.
|
I was tired of Perl and PHP. These languages are pretty simple and anybody can learn it
quickly. You do not need a lot of experience to use Perl or PHP ... That's why I decided
to write this library.
Please click here to consult de CGI++ documentation.
|





